【検索エンジン】便利ですよね。
え?『検索エンジンって何?』って?
皆さん使ってますよね?GoogleとかYahooとか。
キーワードを入力して検索すると色々と出てくるやつあるじゃないですかー。
あれのことです。
その検索エンジンの小規模版を卒研で作っちゃいました。
当時の卒論をベースに記事にまとめていきます。
当時の卒研ベースなので分かり辛い所は大目に見てください。
開発言語
クローラーは以下のいずれかです。
卒研では比較のためすべて使用しましたが、実際に作る時はお好きな言語で開発することをおススメします。
クローラー
- Python + SQL
- Java + SQL
- C# + SQL
検索フォーム
- PHP
- SQL
どんな検索エンジンを作ったのか
そもそも検索エンジンとは複数種類のあるものの総称です。
検索エンジンの種類にはこんなものがあります。
検索エンジンの種類
- ロボット型検索エンジン
- ディレクトリ型検索エンジン
- 分散型検索エンジン
- メタ検索エンジン
それぞれの説明は長くなるので省きます。
詳しく知りたい方はWikipediaを参照してください。
[st-card-ex url="https://ja.wikipedia.org/wiki/%E6%A4%9C%E7%B4%A2%E3%82%A8%E3%83%B3%E3%82%B8%E3%83%B3" target="_blank" rel="nofollow" label="Wiki" name="" bgcolor="red" color="" readmore=""]
で、私が卒研で作成した検索エンジンは
ロボット型検索エンジン
です。
これだけは軽く説明しようと思います。
ロボット型検索エンジン
代表例を先に書くと「Google」の検索エンジンがそうですね。
ロボット型検索エンジンの大きな特徴は「クローラー」を用いる点が挙げられます。
独自のアルゴリズムによってインターネット上に存在するWebページを巡回し、データを収集していくシステムになります。
そのためアルゴリズムは非公開となっています。
検索結果の表示順も独自のアルゴリズムによって決定されますのでこちらの情報も非公開です。
ここで分かる通り、検索エンジンに関する情報は調べたとしてもアルゴリズムは出てきません。
ということで独自のアルゴリズムを、プログラミングを始めて1年半くらいの私が考えて卒研で作りました。
と言っても小規模でかつ簡易的なロボット型検索エンジンなのでアルゴリズムも簡単なものになります。
ロボット型検索エンジンに必要なもの
卒研で作った検索エンジンはクローラー含めDBやら何やらも全てノートパソコンで完結しています。
それほどまでに小規模なので最小構成の検索エンジンになります。
必要なもの
- クローラー
- データベース
- サーバー
だいたいこれくらいです。
クローラーが本命なので他のデータベース(以下DBとします)とサーバーについてを先にお話しします。
データベースとサーバーについて
ここで言うサーバーとはWebサーバーのことを指します。
開発段階ではサーバーとDBの準備に時間は割きたくなかったというのもありますが、純粋に当時はサーバーやDBについての知識が無かったのでXAMPPを使用していました。
XAMPPについてはここでは特に触れません。
詳しくはこちらの方の記事を参考にして下さい!
[st-card-ex url="https://www.javadrive.jp/xampp/" target="_blank" rel="nofollow" label="参考" name="" bgcolor="red" color="" readmore=""]
データベースの構成
作った当時はサーバーとかデータベースの知識なんて無いに等しいわけです。
ということでこちらも最小限の構成!
因みにDBはMySQLを使用していきます。
これがDBの知識がほぼゼロの実力です!(※卒論より引用)

これだけ!
できる検索方法は部分一致のみです!
Webサーバーについて
XAMPPを使うのでApacheを使用することになります。
なので詳しく話すことも無いのでWebサーバーを使う理由を…。

という理由から収集するページを自前で用意することにしたからです。
まぁ、どちらにせよ検索ページが必要なので後々用意する必要がありましたが…。
Webサーバーについてはこのくらいですね。
クローラーを作ろう
いざ作ると言っても、何をどうするんだという話なので考えられる機能を一覧にして書き出してみましょう。
こちらも最小構成なので必要機能は最小限です。
クローラーの必要機能
クローラーを開発する言語は何であっても構いません。
因みにRubyであれば開発に役立つ書籍があったりします。
とは言え、開発する言語によっては【クローラーの開発方法】をまとめているサイトや書籍が無いことの方が多いです。
まずは必要機能を書き出していきましょう。
クローラーの必要機能
- URLへアクセスする機能
- アクセス先からHTML情報を取得する機能
- HTMLタグを解析する機能
基本的な機能であればこの程度の機能でクローラーは作れます。
この中で一番重要な機能は3番の【HTMLタグを解析する機能】です。
大まかに必要なものとして、これら3つを合わせて【スクレイピング技術】が必要になってきます。
少しでも簡単に開発を進めたいのであればPythonをおススメします。
因みに私はC#で開発しました。
現在はRustを使用して新規開発を開始しています。
スクレイピングと正規表現
一番重要な機能ですね。
その中でもHTMLタグを解析する技術が特に重要です。
HTMLタグを解析しないことにはWebページ上のURLにアクセスして情報収集しても良いのか判断できませんからね。
nofollowがついているタグはそのリンク先を収集しないようにしないとなりません。
ではHTMLタグの解析はどうすれば良いのか……。
正規表現
を使用します。
スクレイピング技術については言語によって異なるので詳細は省こうと思います。
正規表現にのみカーソルを合わせていこうと思います。
今回取得する必要があるのはHTMLタグのaタグです。
HTMLの情報をスクレイピングによって取得している前提です。
そうしたら正規表現でaタグのhref要素の中身を取得しましょう。
因みにPythonだと「BeautifulSoup」を使用することによってスクレイピングもタグ解析もできます。
Javaだと「Jsoup」というものがあります。
自分で実装する場合は正規表現ですね。
これで取得できます。
重要なのは【aタグのhref】です。
<a href="https://www.dice-programming-etc.com/dice-diary-202108/">DICEのつぶやき2021年8月</a>これですね。
まずは【href="~"】の部分を取得します。
aタグからの抽出はプログラミング言語によって若干異なるので私が試したやつを記載します。
html=bs4.BeautifulSoup(req.get(url).text,'html.parser')
link=html.select('a[href]')
leng = len(link)
for i in range(leng):
url_link=link[i].get('href')
Match m;
string HRefPattern = "href\\s*=\\s*(?:[\"'](?<1>[^\"']*)[\"']|(?<1>\\S+))";
string[] href = new string[100];
try
{
m = Regex.Match(inputString, HRefPattern,
RegexOptions.IgnoreCase | RegexOptions.Compiled,
TimeSpan.FromSeconds(1));
for (int i=0;m.Success;i++)
{
try
{
string txt = m.Groups[1].Value;
href[i] = txt; // URL
string x = Insert_url.Insert.insert((m.Groups[1].ToString()), ""); //DBへのインサート
m = m.NextMatch();
}
catch
{
break;
}String href=null;
------中略--------
Elements elements = html.select("a");
if (elements == null || elements.toString().length() == 0) {
System.out.println("String must not be empty");
}
else {
for (Element element : elements) {
href=element.attr("href");
こんな感じでaタグの中身を取得します。(確かこれで取得できたはず…。)
卒業研究の時はクローラーの速度比較のため、全く同じ処理をするクローラーをJava、C#、Pythonで開発をしました。
当時の比較結果がこちら。

当時は最適化とかその辺のことは全然知らなかったので作ったままのプログラムで測定しましたが、Pythonがダントツで速かったですね。
ここで抽出したURLをDBへ保存していきます。
SQLで取得したURLを登録
URLの重複は避けたいところなので既に登録されているURLは登録しないSQLを書いていきます。
SQLも分からん!という状況の時に書いたSQLなので不格好なのは許してくださいね。
INSERT INTO url_list(url_all,check_url)
SELECT "URL",0 FROM DUAL
WHERE NOT EXISTS(SELECT * FROM url_list WHERE url_all="URL")これはテーブル【url_list】に重複なしでURLを登録する時に使用します。
- INSERT INTO url_list(url_all,check_url) SELECT "URL",0
- “INSERT INTO url_list(url_all,check_url)”はINSERTするテーブル名と列名を指定している。
- “SELECT "エンコードしたurl",0”の部分は、通常のINSERT構文”INSERT INTO テーブル名(フィールド名,フィールド名) VALUES (値,値)”の”VALUE (値,値)”にあたる部分です。
- FROM DUAL
- DUALを使ってダミーテーブルを使用している。
ただし、DBによっては使えないことがあるため注意が必要。
- DUALを使ってダミーテーブルを使用している。
- WHERE NOT EXISTS(SELECT * FROM url_list WHERE url_all="URL")
- NOT EXISTSを使用して存在しない場合は行を表示するようする。
- SELECT INSERT文であるため表示された行がINSERTされる。
INSERT INTO link_list (url,url_title,url_text)
SELECT "URL", "タイトル", "テキスト" FROM DUAL
WHERE NOT EXISTS(SELECT * FROM url_list WHERE url_all="URL")これはテーブル【link_list】に登録する用ですね。
【url_list】 に登録するSQLと大差ないので説明は省きます。
最後に巡回済みを示すために【url_list】check_urlを更新します。
UPDATE url_list SET check_url="1" WHERE url_all="URL"これだけでSQLは終わり!
あとはプログラムでデータを収集してきてDBへ登録・更新してデータを収集して……の繰り返しです。
これで基本的なクローラーは完成してしまいます。
で、卒研では技術・知識が不足していたのでランキングやらインデックスやらの作成はできませんでした。
その辺のアルゴリズムがとてつもなく複雑だと思うので時間をかけてやっていく必要がありますね。
この機能はクローラーの中枢を担う機能になると思います。
Googleのクローラーが評価する基準もこのランキング機能やインデックスによって構成されているのでは……?と考えていたりします。
クローラーの処理の流れ
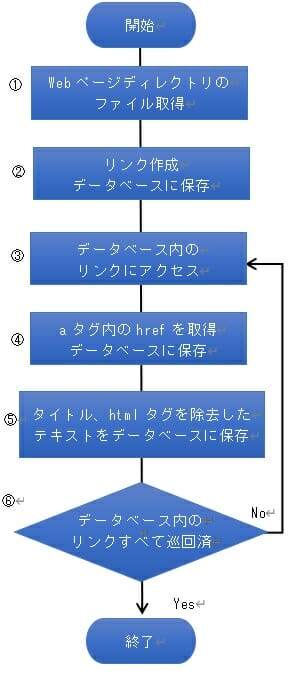
卒研で作ったのはこんな感じの流れです。
これをひたすら繰り返す感じです。
もちろん簡易版なのでアクセス頻度など考えていません。
検索フォームを作ってみる
検索フォームはPHPを使用して作っています。
まぁ、デザイン面はHTMLとCSSなのでPHPは検索する時に使う感じです。
因みにソースコードは紛失してしまったので、画像のみです。
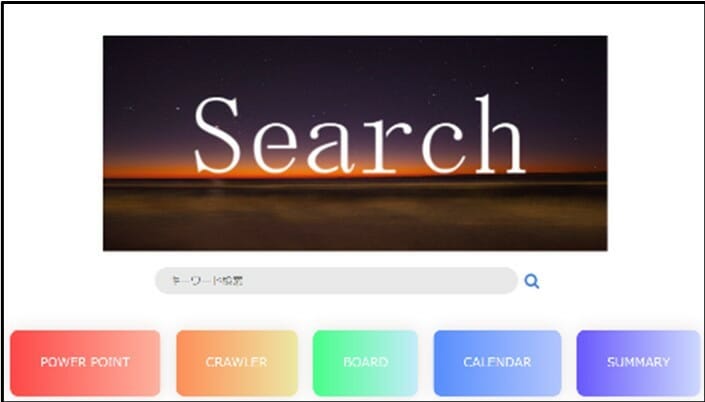
若干……と言うかがっつりGoogleの検索画面を模していることが丸わかりですね。
検索クエリとしては部分一致ですね。
SELECT * FROM link_list WHERE url_title LIKE '%$keyword%'こんな感じです。
で、取得してきたURLとタイトル、HTML内のテキストをベースにGoogleの検索結果と似たようにfor文で表示していく感じですね。
まとめ
はい、卒研で作った検索エンジンはこんな感じです。
就職してから色々と勉強したおかげでこの当時がいかに無知だったかが分かります。
現在は、URL短縮サービスの開発とWordpressのテーマ作成に時間を割いているので、検索エンジン開発は一旦ストップしています。
ただ、いかにWebサイトの表示順位を決定するのかのアルゴリズムを考えているところです。
更に検索時の入力を分析して表示する内容を一覧化しなければならないので、自然言語解析も必要かなぁと悩んでいるところです。
私の理想としてはGoogleの検索エンジンのように結構曖昧な検索キーワードでも検索結果が出せるようになることですね。
最終的には画像検索や、動画検索なども追加して他にはない独自検索エンジンを作りたいところです。